Taux de similarité
Écrit par B. Bathelot, modifié le 11/07/2016Glossaires : Référencement naturel / SEO SEO black hat
Le taux de similarité de contenu est un indicateur de ressemblance entre deux ou plusieurs contenus de nature textuel présents sur Internet. Il est utilisé par les moteurs et notamment Google pour détecter des contenus dupliqués (duplicate content) et appliquer son filtre dédié.
La mesure du taux de similarité peut être utilisée pour identifier les phénomènes de duplication internes à un site web (généralement très faciles à identifier car constitués de contenus souvent strictement identiques sous des URL différentes) ou des phénomènes de duplication externes. Dans ce dernier cas, il peut s'agir pour le moteur d'essayer d'identifier un contenu originel ou de tenter de détecter les pratiques les plus grossières de content spinning dans le domaine du SEO black hat.
Lorsque le taux de similarité dépasse un certain seuil, l'outil d'analyse du moteur peut estimer que les contenus sont identiques et prendre les mesures nécessaires selon la nature du phénomène de duplication. Pour "passer sous le radar" les outils de content spinning les plus évolués utilisent eux aussi la mesure du taux de similarité pour ne publier que des contenus suffisamment différents.
En dehors du contexte SEO, le taux de similarité est également utilisé sur Internet pour détecter les phénomènes de plagiat entre sites Internet ou pour les plagiats éventuels liés aux travaux d'étudiants.
Voir également test de similarité.
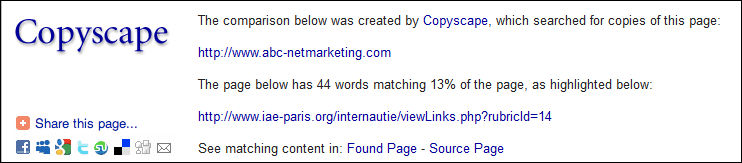
Un exemple basique de calcul de taux de similarité :
Proposer une modification