URL scraping
Écrit par B. Bathelot, le 10/07/2011Glossaires : Référencement naturel / SEO
L'URL scraping est une technique de collecte automatisée d'URL sur un site ou un ensemble de sites qui est souvent utilisée à des fins de black hat SEO.
L'URL scraping permet de collecter les adresses de pages possédant une caractéristique commune qui est identifiée par la présence d'un code ou footprint spécifique.
L'URL scraping peut par exemple être utilisée pour recenser des pages permettant de laisser des avis et commentaires (blogs, guestbooks, livres d'or, articles, etc) et qui ne comprennent pas de balises nofolllow. Une soumission automatique ou plus rarement manuelle de contenus est alors effectuée sur ces pages pour obtenir des backlinks afin d'améliorer le référencement naturel.
L'URL scraping peut également être utilisé pour détecter les pages visibles contenant de statistiques d'audiences comprenant des url de referers pour pratiquer le spam de referers.
Lorsque l'URL scraping se fait à partir du moteur Google ou sur un très gros site, plusieurs dizaines ou centaines de millier d'URL peuvent être "scrapées". Dans ce cas des proxies sont utilisés pour éviter un refus d'accès de la part de Google ou du site visé et les requêtes sont réparties dans le temps.
Un exemple de logiciel dédié à l'URL scraping :
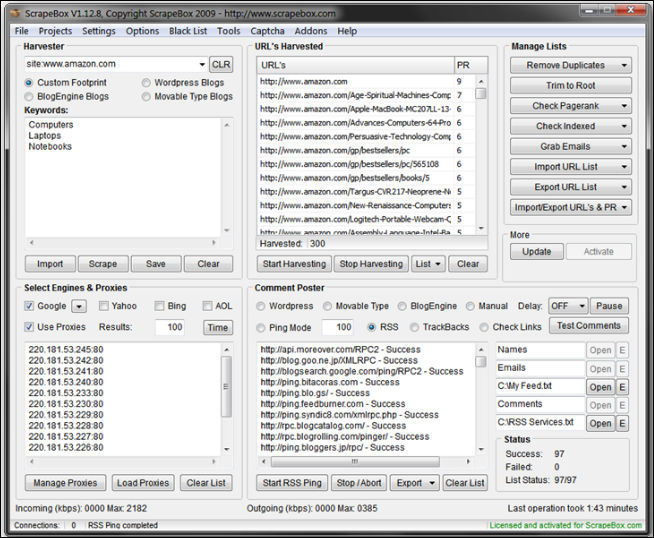
Proposer une modification